|
echelon
0.8.0
|
A handle to an echelon dataset. More...
#include <dataset.hpp>
Public Member Functions | |
| dataset ()=default | |
| Initializes the handle with its null state. | |
| template<typename Container > | |
| void | extend_along (std::size_t dimension_index, const Container &container) |
| Extends the dataset along a given dimension. More... | |
| std::vector< hsize_t > | shape () const |
| The shape of the dataset. | |
| std::size_t | rank () const |
| The rank of the dataset. | |
| type | datatype () const |
| The value type of the dataset. | |
| template<typename... Args> | |
| slice | operator() (Args...args) const |
| Slices the dataset. More... | |
| object_reference | ref () const |
| A echelon object reference to this dataset. | |
| native_handle_type | native_handle () const |
| The underlying HDF5 low-level handle. | |
| operator bool () const | |
| Tests the validity of the handle. | |
| attribute_repository< dataset > | attributes () const |
| The attributes, which are attached to the dataset. | |
| dataset_dimensions | dimensions () const |
| The dimensions of the dataset. | |
Friends | |
| template<typename T > | |
| void | operator<<= (dataset &sink, const T &source) |
| Writes the content of a data source into the dataset. More... | |
| template<typename T > | |
| void | operator<<= (T &sink, const dataset &source) |
| Reads the content of the dataset into a data sink. More... | |
A handle to an echelon dataset.
|
inline |
Extends the dataset along a given dimension.
| Container | type of the container; Container must satisfy the data sink requirements. |
| dimension_index | index of the extended dimension |
| container | container, which is used to fill the new portions of the dataset |
|
inline |
Slices the dataset.
The boundaries of the slice within the dataset are specified by index ranges, which can be constructed using echelon::range. Currently the following index range specifiers are supported (N and M are non-negative integral values and step is a positive integral value):
| index range | semantic |
|---|---|
| range(N,M) | restrict the dimension to the interval 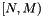 . . |
| range(N,M,step) | restrict the dimension to the interval and only include every step-th value. |
| N | restrict the dimension to the single value N. This is equivalent to range(N,N+1) |
| _ | do not restrict the dimension, but use the full range of indices |
Within the range syntax the wildcard _ can be used as the lower or upper bound to specifiy, that the dimension should not be restricted through this bound.
The number of index range specifiers must match the rank of the dataset.
If an index range only contains one value, the rank of the slice is reduced by one. If none of the index range satisfies this condition, the rank of the slice equals the rank of the dataset.
The following example shows, how a slice can be used to access a portion of a dataset:
It should be noted, that only the sliced portion of the dataset is loaded into the main memory. Therefore slicing is an efficient way to work on large datasets and even allows us to deal with datasets , which do not fit into the main memory.
At the time of writing, slice does support most operations, which are valid on a dataset.
| Args | types of the index range specifiers |
| args | index range specifiers |
|
friend |
Writes the content of a data source into the dataset.
The shape of the data source must match the shape of the dataset.
| T | type of the container; T must satisfy the data source requirements. |
| sink | the dataset, which is used as a sink |
| source | the data source |
|
friend |
Reads the content of the dataset into a data sink.
| T | type of the container; T must satisfy the data sink requirements. |
| sink | the data sink |
| source | the dataset, which is used as a source |
 1.8.11
1.8.11

